
Welcome to My AI Papers Hub
Charter
People
Those I utterly respect!
Researchers of my interest
Entrepreneurs I respect
Companies of my interest
Erudio Bio, Inc. / Tesla / Figure AI / Liquid AI / Mistrial AI / D.Notitia
All papers in reverse chronological order
Optimization
- "Compact Model Parameter Extraction via Derivative-Free Optimization" @ IEEE Access - Rafael Perez Martinez, Masaya Iwamoto, Kelly Woo, Zhengliang Bian, Roberto Tinti, Stephen Boyd & Srabanti Chowdhury @ 24-Jun-2024 (Boyd's homepage, arxiv)
- "Model-Based Deep Learning: On the Intersection of Deep Learning and Optimization" @ IEEE Access - N. Schlezinger, Y. Eldar & S. Boyd @ 05-May-2022 (Boyd's homepage, arxiv)
- "A Heuristic for Optimizing Stochastic Activity Networks with Applications to Statistical Digital Circuit Sizing" @ Optimization and Engineering - S.-J. Kim, S. Boyd, S. Yun, D. Patil & M. Horowitz @ 01-Dec-2007 (Boyd's homepage, Springer)
Convex optimization
- "Optimization Algorithm Design via Electric Circuits" @ NeurIPS 2024 - Stephen P. Boyd, Tetiana Parshakova, Ernest K. Ryu & Jaewook J. Suh @ 04-Nov-2024 (Boyd's homepage, arxiv)
- "A Distributed Method for Fitting Laplacian Regularized Stratified Models" @ Journal of Machine Learning Research - J. Tuck, S. Barratt & S. Boyd @ 26-Apr-2019 (Boyd's homepage, arxiv)
- "Infeasibility Detection in the Alternating Direction Method of Multipliers for Convex Optimization" @ Journal of Optimization Theory and Applications - G. Banjac, P. Goulart, B. Stellato & S. Boyd @ 01-Sep-2018 (Boyd's homepage, IEEE)
- "Distributed Majorization-Minimization for Laplacian Regularized Problems" @ IEEE-CAA Journal of Automatica Sinica - J. Tuck, D. Hallac & S. Boyd @ 27-Mar-2018 (Boyd's homepage, arxiv)
- "Multi-Period Trading via Convex Optimization" @ Foundations and Trends in Optimization - S. Boyd, E. Busseti, S. Diamond, R. Kahn, K. Koh, P. Nystrup & J. Speth @ 01-Aug-2017 (Boyd's homepage, arxiv)
- "Matrix-Free Convex Optimization Modeling" @ Optimization and Its Applications in Control and Data Sciences - S. Diamond and S. Boyd @ 01-Jan-2016 (Boyd's homepage, arxiv)
- "Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers" @ Foundations and Trends in Machine Learning - S. Boyd, N. Parikh, E. Chu, B. Peleato & J. Eckstein @ 01-Jan-2011 (Boyd's homepage, arxiv)
- "A New Method for Design of Robust Digital Circuits" @ International Symposium on Quality Electronic Design (ISQED) 2005 - D. Patil, S. Yun, S.-J. Kim, A. Cheung, M. Horowitz & S. Boyd @ 01-Mar-2005 (Boyd's homepage, IEEE)
- "Design of robust global power and ground networks" @ ACM/SIGDA Symposium on Physical Design (ISPD) 2001 - S. Boyd, L. Vandenberghe, A. El Gamal & S. Yun @ 01-Apr-2001 (Boyd's homepage, ACM)
AI
Fundamentals
-
"How Classification Baseline Works for Deep Metric Learning: A Perspective of Metric Space"
- Yuanqu Mou, Zhengxue Jian, Haiyang Bai & Chang Gou
@ 05-Sep-2024
(OpenReview.net)
abstract
Deep Metric Learning (DML) stands as a powerful technique utilized for training models to capture semantic similarities between data points across various domains, including computer vision, natural language processing, and recommendation systems. Current approaches in DML often prioritize the development of novel network structures or loss functions while overlooking metric properties and the intricate relationship between classification and metric learning. This oversight results in significant time overhead, particularly when the number of categories increases. To address this challenge, we propose extending the loss function used in classification to function as a metric, thereby imposing constraints on the distances between training samples based on the triangle inequality. This approach is akin to proxy-based methods and aims to enhance the efficiency of DML. Drawing inspiration from metrically convex metrics, we introduce the concept of a "weak-metric" to overcome the limitations associated with certain loss functions that cannot be straightforwardly extended to full metrics. This ensures the effectiveness of DML under various circumstances. Furthermore, we extend the Cross Entropy loss function to function as a weak-metric and introduce a novel metric loss derived from Cross Entropy for experimental comparisons with other methods. The results underscore the credibility and reliability of our proposal, showcasing its superiority over state-of-the-art techniques. Notably, our approach also exhibits significantly faster training times as the number of categories increases, making it a compelling choice for large-scale datasets.
- "Classification is a Strong Baseline for Deep Metric Learning" - Andrew Zhai & Hao-Yu Wu @ 30-Nov-2018 (arxiv)
Bio
- "Sequence modeling and design from molecular to genome scale with Evo" - Eric Nguyen, Michael Poli, Matthew G. Durrant, Brian Kang, Dhruva Katrekar, David B. Li, Liam J. Bartie, Armin W. Thomas, Samuel H. King, Garyk Brixi, Jeremy Sullivan, Madelena Y. Ng, Ashley Lewis, Aaron Lou, Stefano Ermon, Stephen A. Baccus, Tina Hernandez-Boussard, Christopher Ré, Patrick D. Hsu & Brian L. Hie (Arc Institute, Department of Computer Science @ Stanford University & Stanford Data Science) @ 15-Nov-2024 (Science)
-
"Geometry-Aware Generative Autoencoders for Warped Riemannian Metric Learning and Generative Modeling on Data Manifolds"
- Xingzhi Sun, Danqi Liao, Kincaid MacDonald, Yanlei Zhang, Chen Liu, Guillaume Huguet, Guy Wolf, Ian Adelstein, Tim G. J. Rudner & Smita Krishnaswamy
@ 16-Oct-2024
(arxiv)
abstract
Rapid growth of high-dimensional datasets in fields such as single-cell RNA sequencing and spatial genomics has led to unprecedented opportunities for scientific discovery, but it also presents unique computational and statistical challenges. Traditional methods struggle with geometry-aware data generation, interpolation along meaningful trajectories, and transporting populations via feasible paths. To address these issues, we introduce Geometry-Aware Generative Autoencoder (GAGA), a novel framework that combines extensible manifold learning with generative modeling. GAGA constructs a neural network embedding space that respects the intrinsic geometries discovered by manifold learning and learns a novel warped Riemannian metric on the data space. This warped metric is derived from both the points on the data manifold and negative samples off the manifold, allowing it to characterize a meaningful geometry across the entire latent space. Using this metric, GAGA can uniformly sample points on the manifold, generate points along geodesics, and interpolate between populations across the learned manifold using geodesic-guided flows. GAGA shows competitive performance in simulated and real-world datasets, including a 30% improvement over the state-of-the-art methods in single-cell population-level trajectory inference.
- "Predicting Gene Ontology Annotations from CAFA Using Distance Machine Learning and Transfer Metric Learning" - Shilpa Choudhary, MD Khaja Shaik, Sivaneasan Bala Krishnan & Sunita Gupta @ 30-Sep-2024 (Wiley)
AI agent
- "Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains" - Vighnesh Subramaniam, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba, Shuang Li & Igor Mordatch (MIT & Google) @ 10-Jan-2025 (arxiv)
- "Agents Are Not Enough" - Chirag Shah & Ryen W. White (University of Washington & Microsoft Research) @ 19-Dec-2024 (arxiv)
- "Agent-as-a-Judge: Evaluate Agents with Agents" - Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Yangyang Shi, Vikas Chandra & Jürgen Schmidhuber (Meta AI & King Abdullah University of Science and Technology (KAUST)) @ 14-Oct-2024 (arxiv)
- "MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering" - Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng & Aleksander Mądry (OpenAI) @ 09-Oct-2024 (arxiv)
- "MMAU: A Holistic Benchmark of Agent Capabilities Across Diverse Domains" - Guoli Yin, Haoping Bai, Shuang Ma, Feng Nan, Yanchao Sun, Zhaoyang Xu, Shen Ma, Jiarui Lu, Xiang Kong, Aonan Zhang, Dian Ang Yap, Yizhe zhang, Karsten Ahnert, Vik Kamath, Mathias Berglund, Dominic Walsh, Tobias Gindele, Juergen Wiest, Zhengfeng Lai, Xiaoming Wang, Jiulong Shan, Meng Cao, Ruoming Pang & Zirui Wang (Apple Inc.) @ 18-Jul-2024 (arxiv)
- "AnalogCoder: Analog Circuit Design via Training-Free Code Generation" - Yao Lai, Sungyoung Lee, Guojin Chen, Souradip Poddar, Mengkang Hu, David Z. Pan & Ping Luo (The University of Hong Kong, The University of Texas at Austin & The Chinese University of Hong Kong) @ 23-May-2024 (arxiv)
LLM
- "Foundations of Large Language Models" - Tong Xiao & Jingbo Zhu (NLP Lab & Northeastern University & NiuTrans Research) @ 16-Jan-2025 (arxiv)
- "Titans: Learning to Memorize at Test Time" - Ali Behrouz, Peilin Zhong & Vahab Mirrokni (Google Research) @ 31-Dec-2024 (arxiv)
- "HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems" - Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen & Ji-Rong Wen (Renmin University of China & Baichuan Intelligent Technology) @ 05-Nov-2024 (arxiv)
-
"To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning arxiv"
@ 18-Sep-2024
(arxiv)
abstract
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra "thinking" really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
- "OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs arxiv" @ 08-Sep-2024 (arxiv)
- "Distilling System 2 into System 1" - Ping Yu, Jing Xu, Jason Weston & Ilia Kulikov (META Fair) @ 24-Jul-2024 (arxiv)
- "Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation" - Tu Vu, Kalpesh Krishna, Salaheddin Alzubi, Chris Tar, Manaal Faruqui & Yun-Hsuan Sung (Google & Google DeepMind & UMass Amherst) @ 15-Jul-2024 (arxiv)
-
"FACTS About Building Retrieval Augmented Generation-based Chatbots"
- Rama Akkiraju, Anbang Xu, Deepak Bora, Tan Yu, Lu An, Vishal Seth, Aaditya Shukla, Pritam Gundecha, Hridhay Mehta, Ashwin Jha, Prithvi Raj, Abhinav Balasubramanian, Murali Maram, Guru Muthusamy, Shivakesh Reddy Annepally, Sidney Knowles, Min Du, Nick Burnett, Sean Javiya, Ashok Marannan, Mamta Kumari, Surbhi Jha, Ethan Dereszenski, Anupam Chakraborty, Subhash Ranjan, Amina Terfai, Anoop Surya, Tracey Mercer, Vinodh Kumar Thanigachalam, Tamar Bar, Sanjana Krishnan, Samy Kilaru, Jasmine Jaksic, Nave Algarici, Jacob Liberman, Joey Conway, Sonu Nayyar & Justin Boitano
(NVIDIA)
@ 10-Jul-2024
(arxiv)
RAG pipeline for Chatbots
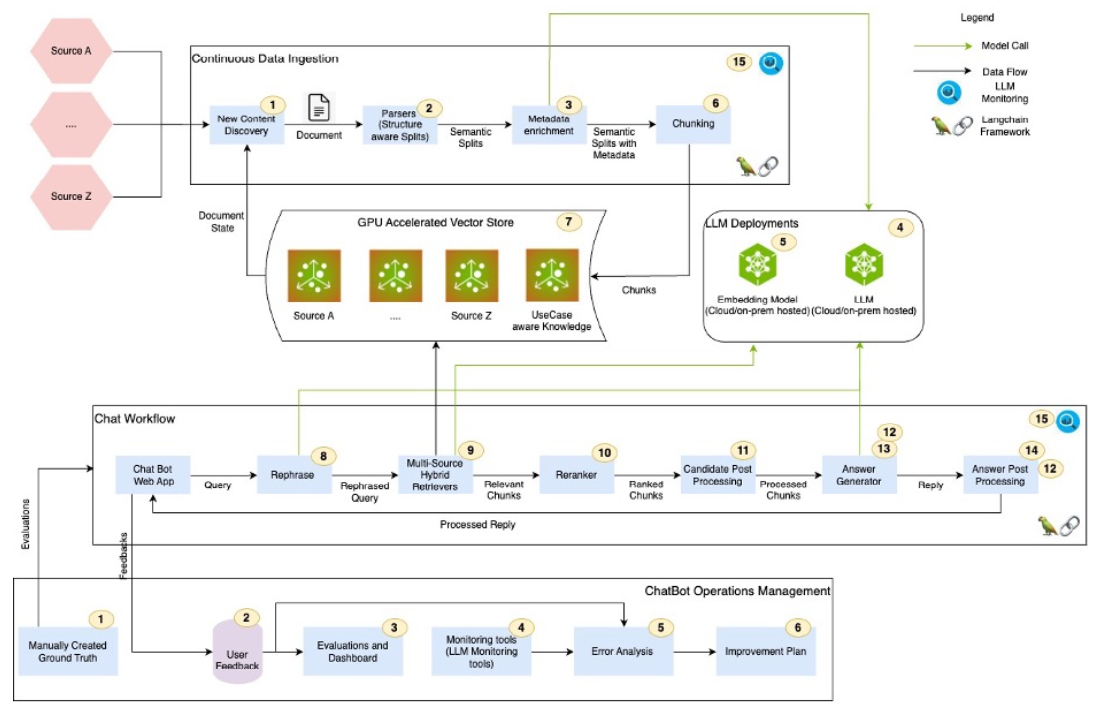
Control Points in a typical RAG pipeline when building Chatbots -
"SWE-bench: Can Language Models Resolve Real-World GitHub Issues?"
- Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press & Karthik Narasimhan
(Princeton University, Princeton Language and Intelligence & University of Chicago)
@ 10-Oct-2023
(arxiv)
RAG pipeline for Chatbots
Control Points in a typical RAG pipeline when building Chatbots - "Attention Is All You Need" - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser & Illia Polosukhin (Google Brain & Google Research) @ 12-Jun-2017 (arxiv)
LLM & intelligence
- "Talking About Large Language Models" - Murray Shanahan @ 07-Dec-2022 (arxiv)
- "Simulacra as Conscious Exotica" - Murray Shanahan @ 19-Feb-2012 (arxiv)
- "Satori Before Singularity" - Murray Shanahan @ 01-Jan-2012 (PDF)
- "The Unreasonable Effectiveness of Data" - Alon Halevy, Peter Norvig & Fernando Pereira (Google) @ 24-Mar-2009 (Google Research)
SLM
- "Mistral AI Released Mistral-Small-Instruct-2409: A Game-Changing Open-Source Language Model Empowering Versatile AI Applications with Unmatched Efficiency and Accessibility" @ 18-Sep-2024 (MarkTechPost, model card)
CV
- "Mask2Map: Vectorized HD Map Construction Using Bird's Eye View Segmentation Masks" - Sehwan Choi, Jungho Kim, Hongjae Shin & Jun Won Choi (Hanyang University & SNU) @ 18-Jul-2024 (arxiv)
DL models
- "Robust flight navigation out of distribution with liquid neural networks" @ 19-Apr-2023 (ScienceRobotics)
- "Improved Variational Autoencoders for Text Modeling using Dilated Convolutions" @ 27-Feb-2017 (arxiv)
- "Generating Sentences from a Continuous Space" @ 19-Nov-2015 (arxiv)
NN models
- "Statistical Mechanics of Neural Networks" - Haim Sompolinsky @ 01-Dec-1988 (Physics Today) (Haim Sompolinsky is a professor of physics at the Racah Institute of Physics of the Hebrew University of Jerusalem.)
Metric learning
- "Self-Taught Metric Learning without Labels" - Sungyeon Kim, Dongwon Kim, Minsu Cho & Suha Kwak (POSTECH) @ 04-May-2022 (arxiv, github, ResearchGate)
- "A Robust and Efficient Doubly Regularized Metric Learning Approach" - Meizhu Liu & Baba C. Vemuri @ 01-Jan-2012 (academia.edu, NIH)
Recommender system
- "Collaborative Filtering for Implicit Feedback Datasets" - Yifan Hu, Yehuda Koren & Chris Volinsky (AT&T Labs & Yahoo! Research) @ 18-Jul-2024 (PDF)
- "Logistic Matrix Factorization for Implicit Feedback Data" - Christopher C. Johnson (Spotify) @ 01-Dec-2014 (PDF)
- "BPR: Bayesian Personalized Ranking from Implicit Feedback" - Steffen Rendle, Christoph Freudenthaler, Zeno Gantner & Lars Schmidt-Thieme @ 09-May-2012 (arxiv)
- "Applications of the conjugate gradient method for implicit feedback collaborative filtering" - Gábor Takács, István Pilászy & Domonkos Tikk @ 23-Oct-2011 (ACM, PDF)
Code repo
AI
- "OpenAI's Swarm" - OpenAI @ 10-Oct-2024 (github)
All papers in reverse chronological order
- "Foundations of Large Language Models" - Tong Xiao & Jingbo Zhu (NLP Lab & Northeastern University & NiuTrans Research) @ 16-Jan-2025 (arxiv)
- "Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains" - Vighnesh Subramaniam, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba, Shuang Li & Igor Mordatch (MIT & Google) @ 10-Jan-2025 (arxiv)
- "Titans: Learning to Memorize at Test Time" - Ali Behrouz, Peilin Zhong & Vahab Mirrokni (Google Research) @ 31-Dec-2024 (arxiv)
- "Agents Are Not Enough" - Chirag Shah & Ryen W. White (University of Washington & Microsoft Research) @ 19-Dec-2024 (arxiv)
- "Sequence modeling and design from molecular to genome scale with Evo" - Eric Nguyen, Michael Poli, Matthew G. Durrant, Brian Kang, Dhruva Katrekar, David B. Li, Liam J. Bartie, Armin W. Thomas, Samuel H. King, Garyk Brixi, Jeremy Sullivan, Madelena Y. Ng, Ashley Lewis, Aaron Lou, Stefano Ermon, Stephen A. Baccus, Tina Hernandez-Boussard, Christopher Ré, Patrick D. Hsu & Brian L. Hie (Arc Institute, Department of Computer Science @ Stanford University & Stanford Data Science) @ 15-Nov-2024 (Science)
- "HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems" - Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen & Ji-Rong Wen (Renmin University of China & Baichuan Intelligent Technology) @ 05-Nov-2024 (arxiv)
- "Optimization Algorithm Design via Electric Circuits" @ NeurIPS 2024 - Stephen P. Boyd, Tetiana Parshakova, Ernest K. Ryu & Jaewook J. Suh @ 04-Nov-2024 (Boyd's homepage, arxiv)
-
"Geometry-Aware Generative Autoencoders for Warped Riemannian Metric Learning and Generative Modeling on Data Manifolds"
- Xingzhi Sun, Danqi Liao, Kincaid MacDonald, Yanlei Zhang, Chen Liu, Guillaume Huguet, Guy Wolf, Ian Adelstein, Tim G. J. Rudner & Smita Krishnaswamy
@ 16-Oct-2024
(arxiv)
abstract
Rapid growth of high-dimensional datasets in fields such as single-cell RNA sequencing and spatial genomics has led to unprecedented opportunities for scientific discovery, but it also presents unique computational and statistical challenges. Traditional methods struggle with geometry-aware data generation, interpolation along meaningful trajectories, and transporting populations via feasible paths. To address these issues, we introduce Geometry-Aware Generative Autoencoder (GAGA), a novel framework that combines extensible manifold learning with generative modeling. GAGA constructs a neural network embedding space that respects the intrinsic geometries discovered by manifold learning and learns a novel warped Riemannian metric on the data space. This warped metric is derived from both the points on the data manifold and negative samples off the manifold, allowing it to characterize a meaningful geometry across the entire latent space. Using this metric, GAGA can uniformly sample points on the manifold, generate points along geodesics, and interpolate between populations across the learned manifold using geodesic-guided flows. GAGA shows competitive performance in simulated and real-world datasets, including a 30% improvement over the state-of-the-art methods in single-cell population-level trajectory inference.
- "Agent-as-a-Judge: Evaluate Agents with Agents" - Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Yangyang Shi, Vikas Chandra & Jürgen Schmidhuber (Meta AI & King Abdullah University of Science and Technology (KAUST)) @ 14-Oct-2024 (arxiv)
- "OpenAI's Swarm" - OpenAI @ 10-Oct-2024 (github)
- "MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering" - Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng & Aleksander Mądry (OpenAI) @ 09-Oct-2024 (arxiv)
- "Predicting Gene Ontology Annotations from CAFA Using Distance Machine Learning and Transfer Metric Learning" - Shilpa Choudhary, MD Khaja Shaik, Sivaneasan Bala Krishnan & Sunita Gupta @ 30-Sep-2024 (Wiley)
-
"To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning arxiv"
@ 18-Sep-2024
(arxiv)
abstract
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra "thinking" really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
- "Mistral AI Released Mistral-Small-Instruct-2409: A Game-Changing Open-Source Language Model Empowering Versatile AI Applications with Unmatched Efficiency and Accessibility" @ 18-Sep-2024 (MarkTechPost, model card)
- "OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs arxiv" @ 08-Sep-2024 (arxiv)
-
"How Classification Baseline Works for Deep Metric Learning: A Perspective of Metric Space"
- Yuanqu Mou, Zhengxue Jian, Haiyang Bai & Chang Gou
@ 05-Sep-2024
(OpenReview.net)
abstract
Deep Metric Learning (DML) stands as a powerful technique utilized for training models to capture semantic similarities between data points across various domains, including computer vision, natural language processing, and recommendation systems. Current approaches in DML often prioritize the development of novel network structures or loss functions while overlooking metric properties and the intricate relationship between classification and metric learning. This oversight results in significant time overhead, particularly when the number of categories increases. To address this challenge, we propose extending the loss function used in classification to function as a metric, thereby imposing constraints on the distances between training samples based on the triangle inequality. This approach is akin to proxy-based methods and aims to enhance the efficiency of DML. Drawing inspiration from metrically convex metrics, we introduce the concept of a "weak-metric" to overcome the limitations associated with certain loss functions that cannot be straightforwardly extended to full metrics. This ensures the effectiveness of DML under various circumstances. Furthermore, we extend the Cross Entropy loss function to function as a weak-metric and introduce a novel metric loss derived from Cross Entropy for experimental comparisons with other methods. The results underscore the credibility and reliability of our proposal, showcasing its superiority over state-of-the-art techniques. Notably, our approach also exhibits significantly faster training times as the number of categories increases, making it a compelling choice for large-scale datasets.
- "Distilling System 2 into System 1" - Ping Yu, Jing Xu, Jason Weston & Ilia Kulikov (META Fair) @ 24-Jul-2024 (arxiv)
- "MMAU: A Holistic Benchmark of Agent Capabilities Across Diverse Domains" - Guoli Yin, Haoping Bai, Shuang Ma, Feng Nan, Yanchao Sun, Zhaoyang Xu, Shen Ma, Jiarui Lu, Xiang Kong, Aonan Zhang, Dian Ang Yap, Yizhe zhang, Karsten Ahnert, Vik Kamath, Mathias Berglund, Dominic Walsh, Tobias Gindele, Juergen Wiest, Zhengfeng Lai, Xiaoming Wang, Jiulong Shan, Meng Cao, Ruoming Pang & Zirui Wang (Apple Inc.) @ 18-Jul-2024 (arxiv)
- "Mask2Map: Vectorized HD Map Construction Using Bird's Eye View Segmentation Masks" - Sehwan Choi, Jungho Kim, Hongjae Shin & Jun Won Choi (Hanyang University & SNU) @ 18-Jul-2024 (arxiv)
- "Collaborative Filtering for Implicit Feedback Datasets" - Yifan Hu, Yehuda Koren & Chris Volinsky (AT&T Labs & Yahoo! Research) @ 18-Jul-2024 (PDF)
- "Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation" - Tu Vu, Kalpesh Krishna, Salaheddin Alzubi, Chris Tar, Manaal Faruqui & Yun-Hsuan Sung (Google & Google DeepMind & UMass Amherst) @ 15-Jul-2024 (arxiv)
-
"FACTS About Building Retrieval Augmented Generation-based Chatbots"
- Rama Akkiraju, Anbang Xu, Deepak Bora, Tan Yu, Lu An, Vishal Seth, Aaditya Shukla, Pritam Gundecha, Hridhay Mehta, Ashwin Jha, Prithvi Raj, Abhinav Balasubramanian, Murali Maram, Guru Muthusamy, Shivakesh Reddy Annepally, Sidney Knowles, Min Du, Nick Burnett, Sean Javiya, Ashok Marannan, Mamta Kumari, Surbhi Jha, Ethan Dereszenski, Anupam Chakraborty, Subhash Ranjan, Amina Terfai, Anoop Surya, Tracey Mercer, Vinodh Kumar Thanigachalam, Tamar Bar, Sanjana Krishnan, Samy Kilaru, Jasmine Jaksic, Nave Algarici, Jacob Liberman, Joey Conway, Sonu Nayyar & Justin Boitano
(NVIDIA)
@ 10-Jul-2024
(arxiv)
RAG pipeline for Chatbots
Control Points in a typical RAG pipeline when building Chatbots - "Compact Model Parameter Extraction via Derivative-Free Optimization" @ IEEE Access - Rafael Perez Martinez, Masaya Iwamoto, Kelly Woo, Zhengliang Bian, Roberto Tinti, Stephen Boyd & Srabanti Chowdhury @ 24-Jun-2024 (Boyd's homepage, arxiv)
- "AnalogCoder: Analog Circuit Design via Training-Free Code Generation" - Yao Lai, Sungyoung Lee, Guojin Chen, Souradip Poddar, Mengkang Hu, David Z. Pan & Ping Luo (The University of Hong Kong, The University of Texas at Austin & The Chinese University of Hong Kong) @ 23-May-2024 (arxiv)
-
"SWE-bench: Can Language Models Resolve Real-World GitHub Issues?"
- Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press & Karthik Narasimhan
(Princeton University, Princeton Language and Intelligence & University of Chicago)
@ 10-Oct-2023
(arxiv)
RAG pipeline for Chatbots
Control Points in a typical RAG pipeline when building Chatbots - "Robust flight navigation out of distribution with liquid neural networks" @ 19-Apr-2023 (ScienceRobotics)
- "Talking About Large Language Models" - Murray Shanahan @ 07-Dec-2022 (arxiv)
- "Model-Based Deep Learning: On the Intersection of Deep Learning and Optimization" @ IEEE Access - N. Schlezinger, Y. Eldar & S. Boyd @ 05-May-2022 (Boyd's homepage, arxiv)
- "Self-Taught Metric Learning without Labels" - Sungyeon Kim, Dongwon Kim, Minsu Cho & Suha Kwak (POSTECH) @ 04-May-2022 (arxiv, github, ResearchGate)
- "A Distributed Method for Fitting Laplacian Regularized Stratified Models" @ Journal of Machine Learning Research - J. Tuck, S. Barratt & S. Boyd @ 26-Apr-2019 (Boyd's homepage, arxiv)
- "Classification is a Strong Baseline for Deep Metric Learning" - Andrew Zhai & Hao-Yu Wu @ 30-Nov-2018 (arxiv)
- "Infeasibility Detection in the Alternating Direction Method of Multipliers for Convex Optimization" @ Journal of Optimization Theory and Applications - G. Banjac, P. Goulart, B. Stellato & S. Boyd @ 01-Sep-2018 (Boyd's homepage, IEEE)
- "Distributed Majorization-Minimization for Laplacian Regularized Problems" @ IEEE-CAA Journal of Automatica Sinica - J. Tuck, D. Hallac & S. Boyd @ 27-Mar-2018 (Boyd's homepage, arxiv)
- "Multi-Period Trading via Convex Optimization" @ Foundations and Trends in Optimization - S. Boyd, E. Busseti, S. Diamond, R. Kahn, K. Koh, P. Nystrup & J. Speth @ 01-Aug-2017 (Boyd's homepage, arxiv)
- "Attention Is All You Need" - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser & Illia Polosukhin (Google Brain & Google Research) @ 12-Jun-2017 (arxiv)
- "Improved Variational Autoencoders for Text Modeling using Dilated Convolutions" @ 27-Feb-2017 (arxiv)
- "Matrix-Free Convex Optimization Modeling" @ Optimization and Its Applications in Control and Data Sciences - S. Diamond and S. Boyd @ 01-Jan-2016 (Boyd's homepage, arxiv)
- "Generating Sentences from a Continuous Space" @ 19-Nov-2015 (arxiv)
- "Logistic Matrix Factorization for Implicit Feedback Data" - Christopher C. Johnson (Spotify) @ 01-Dec-2014 (PDF)
- "BPR: Bayesian Personalized Ranking from Implicit Feedback" - Steffen Rendle, Christoph Freudenthaler, Zeno Gantner & Lars Schmidt-Thieme @ 09-May-2012 (arxiv)
- "Simulacra as Conscious Exotica" - Murray Shanahan @ 19-Feb-2012 (arxiv)
- "A Robust and Efficient Doubly Regularized Metric Learning Approach" - Meizhu Liu & Baba C. Vemuri @ 01-Jan-2012 (academia.edu, NIH)
- "Satori Before Singularity" - Murray Shanahan @ 01-Jan-2012 (PDF)
- "Applications of the conjugate gradient method for implicit feedback collaborative filtering" - Gábor Takács, István Pilászy & Domonkos Tikk @ 23-Oct-2011 (ACM, PDF)
- "Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers" @ Foundations and Trends in Machine Learning - S. Boyd, N. Parikh, E. Chu, B. Peleato & J. Eckstein @ 01-Jan-2011 (Boyd's homepage, arxiv)
- "The Unreasonable Effectiveness of Data" - Alon Halevy, Peter Norvig & Fernando Pereira (Google) @ 24-Mar-2009 (Google Research)
- "A Heuristic for Optimizing Stochastic Activity Networks with Applications to Statistical Digital Circuit Sizing" @ Optimization and Engineering - S.-J. Kim, S. Boyd, S. Yun, D. Patil & M. Horowitz @ 01-Dec-2007 (Boyd's homepage, Springer)
- "A New Method for Design of Robust Digital Circuits" @ International Symposium on Quality Electronic Design (ISQED) 2005 - D. Patil, S. Yun, S.-J. Kim, A. Cheung, M. Horowitz & S. Boyd @ 01-Mar-2005 (Boyd's homepage, IEEE)
- "Design of robust global power and ground networks" @ ACM/SIGDA Symposium on Physical Design (ISPD) 2001 - S. Boyd, L. Vandenberghe, A. El Gamal & S. Yun @ 01-Apr-2001 (Boyd's homepage, ACM)
- "Statistical Mechanics of Neural Networks" - Haim Sompolinsky @ 01-Dec-1988 (Physics Today) (Haim Sompolinsky is a professor of physics at the Racah Institute of Physics of the Hebrew University of Jerusalem.)