
MIT-Invented Liquid Neural Networks - A Game-Changer for the Future of LLMs
posted: 06-Oct-2024 & updated: 11-Jul-2025
NotebookLM Podcasts
The Hidden Cost of AI Progress
The pace of AI development, particularly in Large Language Models (LLMs), has been nothing short of extraordinary. As someone who has interacted extensively with key LLM services — Anthropic’s Claude, OpenAI’s ChatGPT, Google’s Gemini, Mistral’s Mistral, X’s Grok, Perplexity AI, and Midjourney for (lots of) fun having AI drawing creative images — I’ve been astounded not only by their rapid advancement but by their vast capabilities. Yet, after this first-hand experience, I now believe that the impact of AI’s evolution is likely to be far greater than I originally imagined.
But for this post, I want to focus on just one of (a handful of) critical aspects of LLMs: their massive energy consumption, largely driven by a very specific DL driven attention mechanism, so called Transformer architecture, that powers them. (I will write more on the topic later in other blog posts; I wrote Beyond Models – Why Domain Insight and Quality Data Will Define AI’s Future 4 months after this blog for one of the other aspects about LLM that I just mentioned!)
The amount of energy consumed by entities providing LLM services is staggering. OpenAI, for instance, reportedly loses money on each inference, even with customer charges for their advanced models. This burden, I believe, will eventually fall on small businesses relying on these APIs, leading to unsustainable costs.
Figures like Sam Altman are seeking trillions in investments to build more data centers and even semiconductor manufacturing facilities. Some have even speculated that AI’s future could rely on nuclear fusion for power. However, I don’t believe that any economy can thrive on limitless energy consumption. This path seems unsustainable; it doesn’t take a genius to recognize that.
Energy dilemma
I’ve had discussions with entrepreneurs in the nuclear fusion space, and while there’s excitement, the technology isn’t commercially viable yet. The most optimistic estimates suggest it could become a reality by 2035, with some projections extending to 2050. With such uncertainty around future energy solutions, it’s imperative that AI research shifts its focus toward reducing energy consumption now.
One potential solution is model compaction—streamlining models to make them more efficient without sacrificing performance. While I can’t offer specific technical solutions here in this post, many researchers are already making strides in this area. Reducing the number of neural connections that need to be activated during each inference could be key to minimizing the energy demand.
Current LLMs excel at general natural language tasks because they’ve been trained on vast amounts of data, learning virtually every grammatical and conversational structure. But do we need this full capacity for every use case?
LLMs in specific applications
For example, during my recent business development efforts at Erudio Bio, Inc., I spoke with several leading medical professionals at South Korea’s largest hospitals. Many expressed interest in LLMs for automating tasks like charting. While LLMs are capable of handling natural language input, do they really need their full linguistic capabilities to handle something as specific as medical charting? Probably not.
This observation extends beyond the medical field. For most use cases, the extensive language understanding of LLMs is neither necessary nor sufficient. This suggests a natural evolution toward lighter models, fine-tuned for specific applications, such as charting for medical professionals. You can get a glimpse of it, e.g., Llama 3.2: Revolutionizing edge AI and vision with open, customizable models.
By the way, according to the above analysis, in the coming years data may prove even more crucial than today’s impressive large language models. The growing importance of data in shaping AI capabilities will be explored further in upcoming posts.
Liquid neural networks (LNNs)
This brings me to a breakthrough that could address the very issues I’ve been grappling with; I accidentally stumbled upon this article a few days ago - MIT spinoff Liquid debuts non-transformer AI models and they’re already state-of-the-art. Their innovative architecture doesn’t require the constant toggling of GPU circuits, as Transformers do. – This article is listed LLM @ AI Insight.
The energy savings are impressive, and the speed of inference is another game-changer. - Look at below figure from the article. - Liquid AI delivers results instantly, in stark contrast to Transformer-based models, which process tokens very slowly; you can practically read the output as it generates if I exaggerate (quite) a bit.
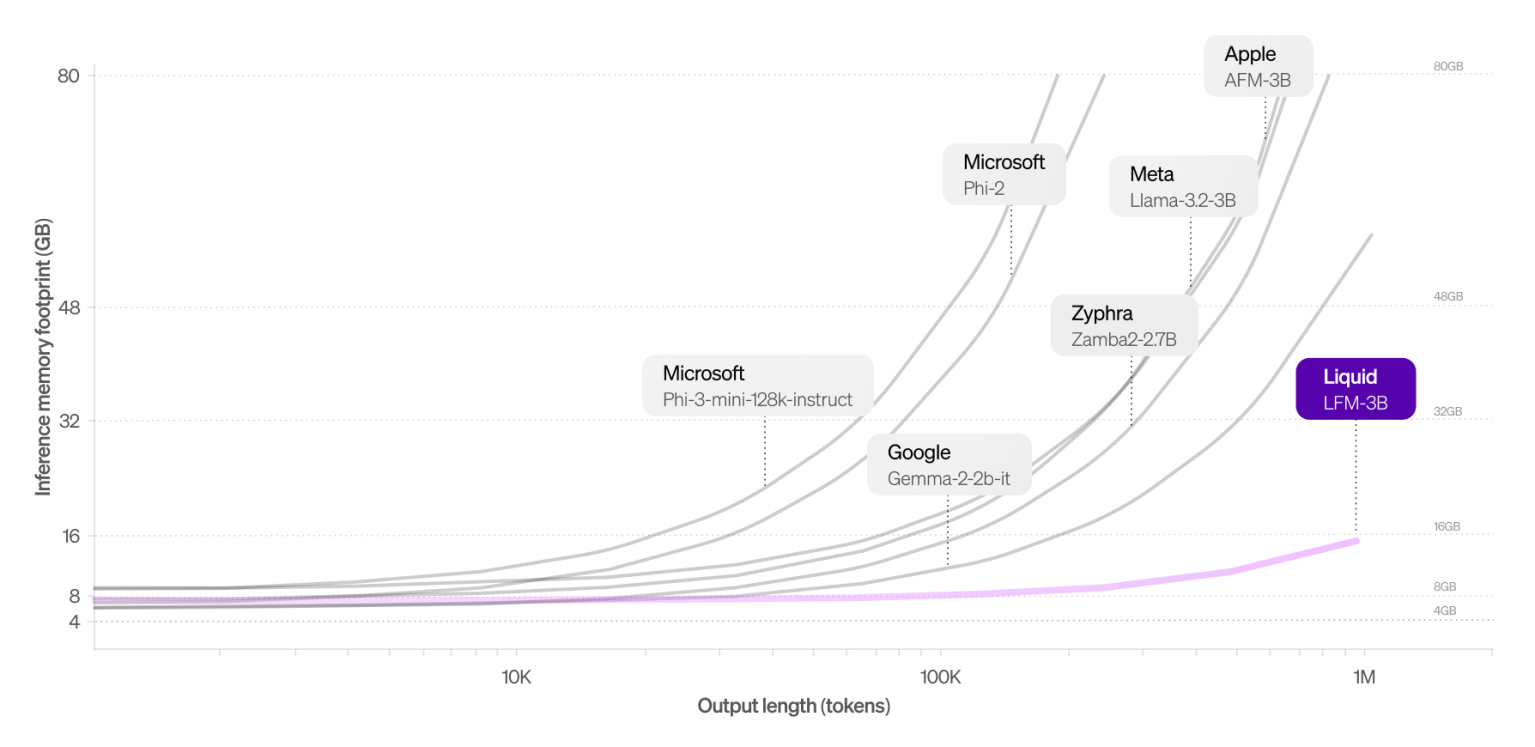
This could very well be the solution I’ve been searching for—a (way) more energy-efficient, (way) faster approach to AI that doesn’t sacrifice performance. Liquid Neural Networks may hold the key to a sustainable future for LLMs, and I’m excited to see where this technology leads.
Conclusion
As we continue to push the boundaries of AI capabilities, it’s crucial that we also focus on making these technologies more sustainable and accessible. The Liquid Neural Network and similar innovations in model efficiency could be the solution we’ve been looking for, paving the way for a new generation of powerful yet energy-efficient AI systems.
In the coming years, we may see a shift towards more specialized, efficient models tailored to specific tasks, with data playing an increasingly critical role in their development and deployment. This evolution could democratize AI technology, making it more accessible to businesses and developers of all sizes.
The future of AI is not just about raw power, but about intelligent, efficient systems that can deliver amazing results without breaking the bank—or the power grid.